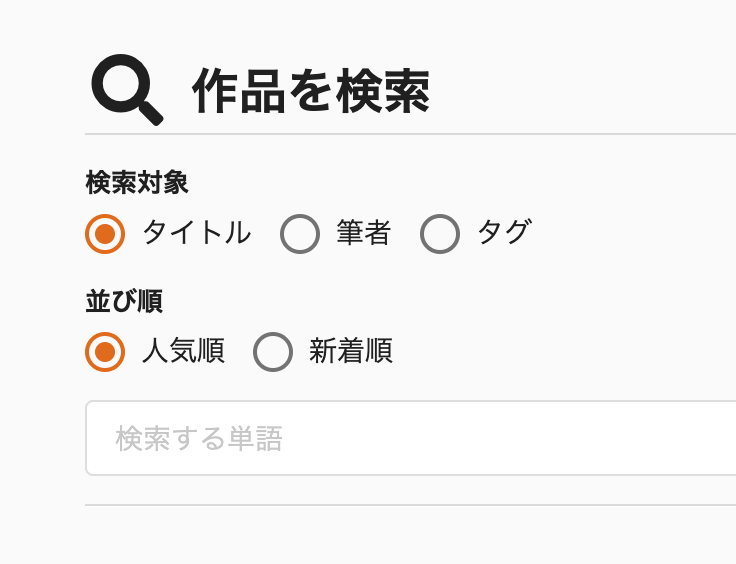
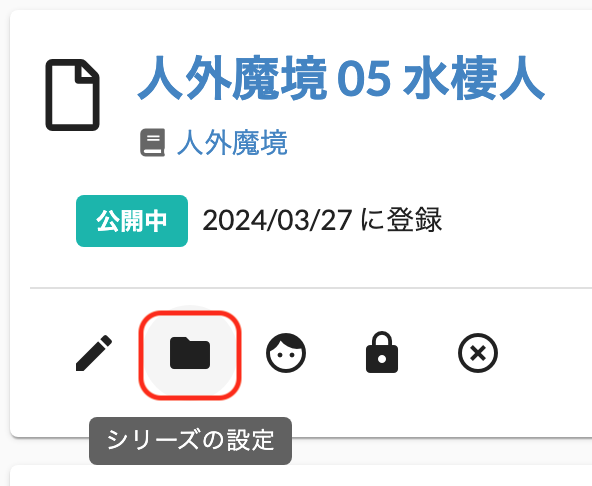
今までシリーズから作品を削除する際には、作品一覧の画面から「シリーズの設定」を選んで、選択されているシリーズを解除する、という(面倒な)操作が必要でした。
今後はシリーズ一覧画面から、それぞれのシリーズの「シリーズの並び替え・編集」を選ぶと、
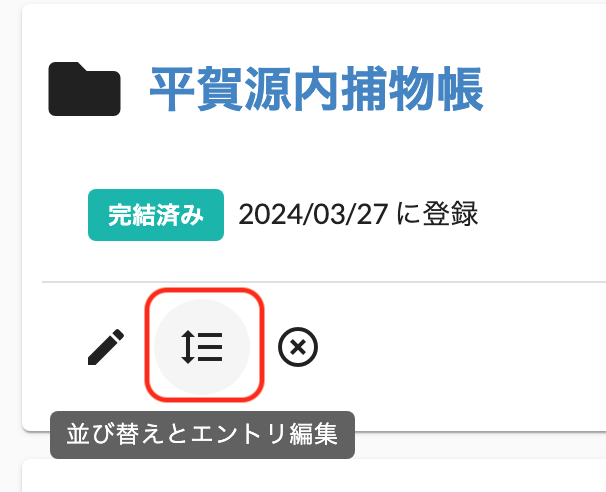
シリーズに登録されたそれぞれの作品の横に「削除ボタン」が表示されるようになったので、そこから作品を当該シリーズから削除できるようになりました。

もちろんシリーズから作品を削除するだけで、作品そのものが削除されるわけではないことにご注意ください。
今までシリーズから作品を削除する際には、作品一覧の画面から「シリーズの設定」を選んで、選択されているシリーズを解除する、という(面倒な)操作が必要でした。
今後はシリーズ一覧画面から、それぞれのシリーズの「シリーズの並び替え・編集」を選ぶと、
シリーズに登録されたそれぞれの作品の横に「削除ボタン」が表示されるようになったので、そこから作品を当該シリーズから削除できるようになりました。
もちろんシリーズから作品を削除するだけで、作品そのものが削除されるわけではないことにご注意ください。
2023年の中旬ごろ、HomebrewがBigSurなどの古いMacOSをサポートから外してしまいました。
しばらくは「なんとかなるさ!」と使っていたのですが、半年もしないうちに重要なパッケージが更新できなくなり…
特に痛かったのは、libheifが更新できなくなって、ImageMagicでavifを扱えなくなったことでした。
そこで古いOSもサポートしていると噂のMacPortsに移行することに。
他の移行先としてnixなども考えましたが、ちょっと調べた感じだと「まだ過渡期なのかな」と思ったので、無難にMacPortsにしました。
で、実際に使ってみたら、拍子抜けするぐらい、普通に移行できました。
しかし、やはり一部ハマったものもあったので、その経験を残しておきます。
ハマりポイントは2つで、自分の場合はcargo-edit(Rust)とfabric(Python3)でした。
MacPortsを運用してしばらくして、Rustのcargo-editというcrateのインストールに失敗することに気付きました。
エラーメッセージを見ると、libiconv.dyldという動的ライブラリのリンクに失敗している模様です。
で、どうもそのリンク先が、MacPortsが管理するlibiconvっぽい…
MacPortsでlibiconvをインストールした覚えはないのですが、広く使われてる文字列変換のライブラリなので、まあなにかのついでにインストールされたのでしょう。それがリンクされて、エラーになったみたいです。
エラーになる理由は、MacPortsでインストールされるlibiconvが、世間一般に公開されている「普通の」libiconvとは、ちょっとだけ異なるから。
なんか他のエコシステムのlibiconvと衝突しないように、いくつかの関数が別名で登録されているらしいのですね。
だからこれをリンク先の動的ライブラリとして選択されてしまうと、リンクエラーになってしまうわけです。
なにが異なるのかは、
nm -a /opt/local/lib/libiconv.dylib | grep iconv nm -a /usr/local/lib/libiconv.dylib | grep iconv
の出力結果を比べたらわかるはずですが、実際にやってみたら「アレ? 別に変わったところはないけど?」という感じでした。
でもまあ、リンクエラーが起きてるんで、なんか違うんでしょう(笑)。
そういうわけで、MacPortsの外の世界のプログラムにlibiconvをリンクするときは、MacPortsが使っている(特別仕様の)libiconvをリンクさせないようにする必要があります。
今回トラブったcargo-editについても、DYLD_LIBRARY_PATHが最初に/opt/local/libを探す仕様になっているせいで、そのままコンパイルするとリンクエラーになるわけです。とはいえ、DYLD_LIBRARY_PATHの上書きは、他のトラブルを起こすことが多いので避けたいところです。
これを解決する方法として、自分の環境では次の2つがうまくいきました。
1つ目は、Rust固有の環境変数を使うもの。
幸いなことに、RustにはRUSTFLAGSという環境変数を通じて、コンパイル時のオプションを渡せる仕組みが用意されています。これを使ってリンク先を変更することができました。
.zshrcとかに、
export RUSTFLAGS="-L/usr/local/lib"
を付け足せばOKです。
もちろんBigSurでは/usr/local/libにlibiconvは入っていないので、ソースからコンパイルして、/usr/local/lib/にインストールしました。
./configure --prefix=/usr/local && make && make install
2つ目の方法はもっと簡単で、cargo-editをインストールするときだけMacPortsのlibiconvを無効にする、という方法。
# いったん無効にする sudo port -f deactivate libiconv # cargo-editをインストール(システム依存のlibiconvが使われる) cargo install cargo-edit # 終わったら再び有効にする sudo port activate libiconv
こうすると、MacPorts以外のlibiconvにリンクしてくれます。
自前で/usr/local/libなどにインストールしてない状態でもうまくいったので、BigSurのどっかしらに、普通のlibiconvがあるんでしょう(笑)。
これでcargo-editはインストールできました。
ただ自分の環境では、これで終わりではなく、その後にcargo-edit系のコマンド(upgrade, add, rm, set-version)を実行したら、また次のようなエラーが出ました。
~/.cargo/registry/index/github.com-1ecc6299db9ec823 is unusable due to having an invalid HEAD reference: reference 'refs/heads/main' not found; class=Reference (4); code=NotFound (-3)
なんかcargo-editに関するgithubのレポジトリ情報が~/.cargo以下に適切に配置されていない、みたいなエラーです。
最近のcargoは、パッケージを管理するcrates-ioというサーバーとの通信に、sparseというプロトコルを使うようになったらしいのですが、cargo-editをインストールする際にもこのプロトコルが使われたことで、githubのrepositoryが~/.cargo/registry以下に適切に登録されなかったっぽいです。
以前のcargoは、巨大なリポジトリをgitプロトコルでローカルに引っ張ってくる仕組みで、その際レポジトリの構造がローカル環境にも配置されていたのでしょう。
しかしcargoのプロトコルの刷新で、それがなくなったことにより、このエラーが出たのだと思います。
エラーを見る限りcargo-editはローカルにgit-repositoryが配置されてないと動かないらしいので、最初にcargo install cargo-editするときだけは、gitプロトコルでcrates-ioと通信するようにします。
これも2つの解決方法があって、1つはCargo.tomlに
[registries.crates-io] protocol = "git" #protocol = "sparse"
と書く方法。もちろん終わったら"sparse"側を有効にします。
もう一つは環境変数CARGO_REGISTRIES_CRATES_IO_PROTOCOLをセットする方法で、.zshrcなどに
export CARGO_REGISTRIES_CRATES_IO_PROTOCOL="git"
と書いておきます。
こうした上で、cargo uninstall cargo-editしてから、cargo install cargo-editすると、正常にインストール&起動するようになりました。
cargo-editほど大変ではありませんでしたが、fabricもすんなりとは動きませんでした。
最初はMacPortsをfabricで検索したら、pythonのそれぞれのバージョンごとに用意されていることがわかったので、素直にそれをインストールしました。
しかし実際に使ってみると、いくつかの処理がエラーで動きませんでした。
そこでpython3とpip3はMacPortsでインストールし、fabricだけpip3でインストールするようにしたら上手くいきました。原因はわかりません(笑)。
ちなみにMacPorts経由でインストールしたpipでインストールするfabコマンドは、/opt/local/Library/Frameworks/Python.framework/Versions/3.xx/bin/にインストールされるので、sudoで実行する必要があります。本当はvenvとか使ったほうが良いんでしょうが、面倒なのでスキップしました。
# python3とpip3をインストール sudo port install py311 pip-3.11 # pip, pip3ともにpip-3.11を使用 sudo port select --set pip pip-3.11 sudo port select --set pip3 pip-3.11 # Macportsのpipでfabricをインストール(sudoに注意) sudo pip install fabric
小さな修正ですが、作品のビューアー下部に表示されるシリーズ情報から、以下のようにシリーズ内の別の作品に移動できるようになりました(これまではシリーズページをわざわざ開く必要がありました)。
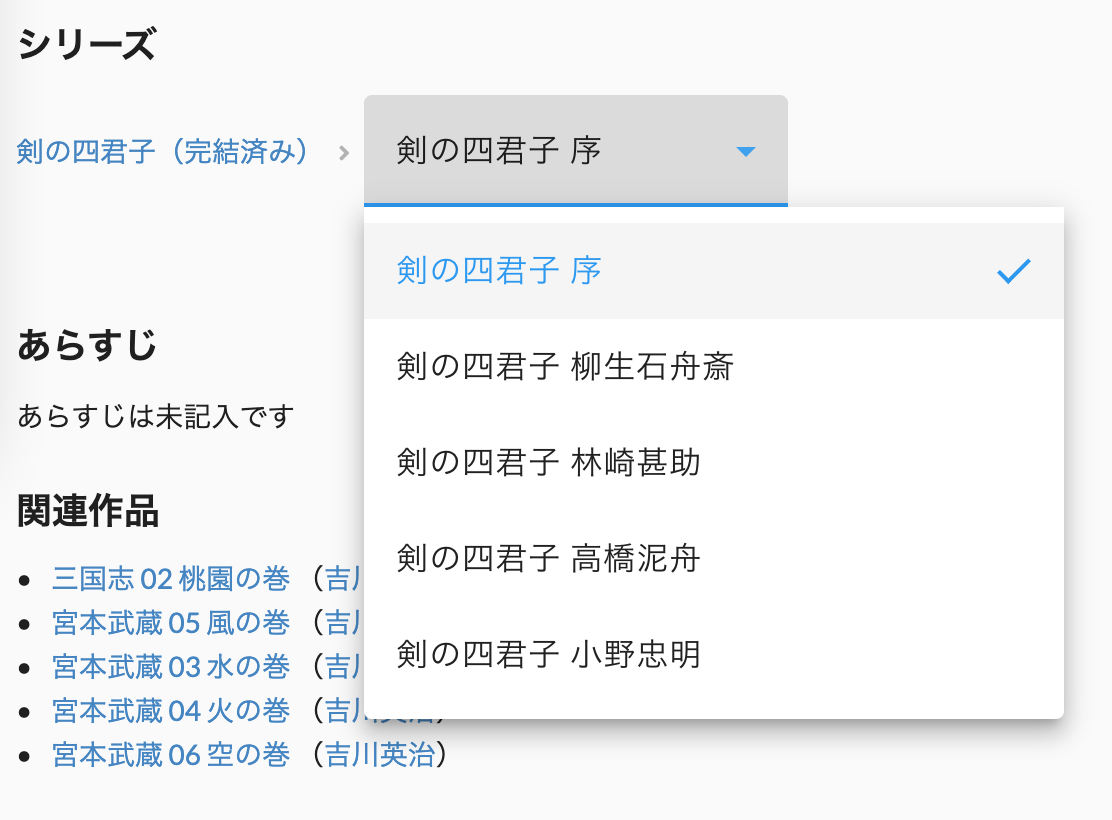
ぜひ使ってみて下さい。
以前、青空文庫の作品をシリーズにまとめた、という記事を書きました。
今回はその第二弾です(ちなみに、鏡の国のアリスは青空文庫ではなく、プロジェクト杉田玄白の作品です)。
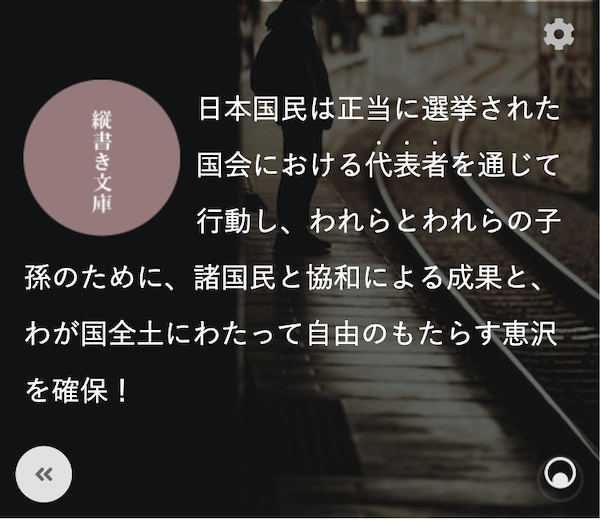
縦書き文庫にて「ドラマモード」の提供が開始されました。
ドラマモードは、背景画像と、キャラクターのアバターと、アニメーションテキストで語られる表示モードです。
ようするに、ビジュアルノベルみたいな表示ができるモードですね。
動作サンプルはhttps://tb.antiscroll.com/dramas/administrator/24548からどうぞ。
また記述方法についての概要は、ヘルプのドラマモードって?を確認してください。

投稿フォームの入力フォーマットという項目を「ドラマ記法」にして投稿してください。
以前、アマチュアとプロの小説の比較について書きましたが、その中で「アマチュアは時間の記述が少ない傾向にある」と述べました。
今回作成したドラマモードでは、背景画像を表示できるので、それによって時間と場所の変更を、文章に頼らず読者に伝えることが可能になります。
またセリフは発言者を明示して書くので、どの発言が誰の発言なのかという問題について、読者は文脈を注意深く読む必要がなくなります。
作品にキャラクターを登録すれば、アバターや名前のクリックで、そのキャラクターの説明が表示されるので「えっと、この人って誰だっけ」みたいなこともなくなります。
補足説明が必要ならTIPというリンクも入れられます。チュンソフトのゲーム「街」で有名な、あの便利機能ですね。


もちろん、これまで通り、ルビや圏点なども普通に使用できます。

初期設定では「横書き」にしていますが、表示設定から「縦書き」にすることも可能です。読みやすいかどうかは別として…

ちなみに「表示設定」からは、縦書きや横書き、文字送りの速さ、文字サイズ、フォント、行間サイズなどを変更できます。

その他にも、縦書き文庫で使える記法は全て使えます。



通常のビジュアルノベルの組版よりは、かなり表現力が豊かなのではないでしょうか(使うかどうかは別として)。

一方で、市販のゲームのような凝った特殊効果みたいなものはありません。音楽や効果音もありません。
ただ通常の本を読むのと同じような感覚だけど、古典的な小説よりは少しだけ親切、みたいな位置を考えています。
今のブラウザだと、音も頑張れば鳴らせなると思うのですが、それをしないのは、小説をスキマ時間に(主にスマホで)読んでもらいたいからです。
というのも、音が出ると、イヤホンを付けなきゃいけないじゃないですか。そういう「一手間」があると、スキマ時間に敬遠される気がしませんか。
だから、ただ起動し、タップするだけで読めるけど、字面だけの小説よりは(ちょっとだけ)疲れない。そういう感じにできたらいいなあと思います。
作品ページのURLの末尾に?p={ページ番号}を付けると、そのページ番号から作品を開けるようになりました。
例えば、夏目漱石の「こころ」の10ページ目を開くリンクは、次のようになります。
https://tb.antiscroll.com/novels/library/6162?p=10
「管理ページ > しおり」で表示される、それぞれのリンクをクリックすると、しおりを挟んだページから再開されるようになりました。
これまでそうじゃなかったのが変だったのですが。。。
ちなみにページを指定したリンクを他人と共有するのは、オススメできません。
なんでかというと、ページの縦横サイズは、端末の解像度によって変わるからです。
例えばスマホでは、1ページのサイズが、PCに比べて(とても)小さくなりますよね。
なので、PCで2ページ目だった内容が、スマホだと10ページ目ぐらいだったり、みたいなことになります。
というわけで、ツイッターとかで「このページを読んで!」みたいな感じで引用リンクを貼っても、あんまり意味がないことに注意してください。
少し前にブログで「wasmではjsと非同期のやり取りをするのが難しい」と書いたのですが、この技術的な課題をなんとか解決できたので、組版の完了したページを(全ページの計算の完了を待たずに)表示できるようになりました。
これによって、すべての作品が0.1 ~ 0.2秒ぐらいで表示されるようになり、大幅に使用感が改善されたと思います。
実はjsと非同期にやり取りする部分のコードのサンプルは、wasm_bindgenのサンプルに入っています。
https://github.com/rustwasm/wasm-bindgen/tree/main/examples/request-animation-frame
肝要なところを抜き出すと以下のようになります。
pub fn run() { let f = Rc::new(RefCell::new(None)); let g = f.clone(); let mut i = 0; *g.borrow_mut() = Some(Closure::new(|| { if i >= 300 { let _ = f.take(); return; } i += 1; request_animation_frame(f.borrow().as_ref().unwrap()); })); request_animation_frame(g.borrow().as_ref().unwrap()); }
fとgはともにクロージャーを保持する参照カウント付きのポインタなのですが、gは最初にクロージャーを走らせるためだけに使います。
gはrunの終了後にクロージャーの参照カウントを減らしますが、もう一方のポインタfはクロージャーの中で再帰的に参照され続けるため、何もしないとこのクロージャーに対する参照カウントは永遠にゼロにならず、解放されなくなってしまいます。
なのでreqest_animation_frameの処理を抜けるタイミングで、中身をf.take()で取り出し、スコープを抜けたところで解放されるようにしているわけですね。
基本は理解できるのですが、nehanの場合、上のサンプルにおけるクロージャーの自由変数が、もうちょっと複雑なデータになっていまして、これだけだと動かない部分があり、ハマっていたのです…
しかしまあ、色々と頑張ったら、なんとか動くようになったので、無事に縦書き文庫のビューアーが(以前と同じく)非同期にページを表示できるようになりました。
ちなみに上のrequest_animation_frameはもちろんjsの関数ではなく、rust側のweb_sysパッケージが提供している関数でして、たぶんですがrust側のデータをjs側のデータにいちいち「お直し」する処理が含まれると思われるため、あんまりたくさん呼ぶのはよくなさそうです。
なので、縦書き文庫の場合は、数十ページぐらい組版し、まとめて送信することで、jsとrust間の通信回数を減らすようにしています。
非同期処理に切り替えた結果、全ページを組版するのにかかる時間は、一度にすべて組版してから送信する方式よりは(当たり前ですが)少しだけ遅くなりました。
しかし、せいぜい5% ~ 10%ぐらいの遅延なので、許容範囲だと思います。
なにより作品を開いてから「しばらくお待ち下さい」の表示がほとんどなくなり、一瞬で作品が表示されるメリットのほうが遥かに大きいです。
読者の離脱率も、大きく改善されるものと思われます。